Campione casuale semplice
Che cos'è un campione casuale semplice?
Un campione casuale semplice è un sottoinsieme di una popolazione statistica in cui ogni membro del sottoinsieme ha la stessa probabilità di essere scelto. Un semplice campione casuale è pensato per essere una rappresentazione imparziale di un gruppo.
Punti chiave
- Un semplice campione casuale prende un piccolo, porzione casuale dell'intera popolazione per rappresentare l'intero set di dati, dove ogni membro ha la stessa probabilità di essere scelto.
- I ricercatori possono creare un semplice campione casuale utilizzando metodi come lotterie o estrazioni casuali.
- Un errore di campionamento può verificarsi con un semplice campione casuale se il campione non riflette accuratamente la popolazione che dovrebbe rappresentare.
Campione casuale semplice
Comprensione del campione casuale semplice
I ricercatori possono creare un semplice campione casuale utilizzando un paio di metodi. Con il metodo della lotteria, ad ogni membro della popolazione viene assegnato un numero, dopodiché i numeri vengono scelti a caso.
Un esempio di un semplice campione casuale sarebbero i nomi di 25 dipendenti scelti a caso da un'azienda di 250 dipendenti. In questo caso, la popolazione è tutta 250 dipendenti, e il campione è casuale perché ogni dipendente ha la stessa probabilità di essere scelto. Il campionamento casuale viene utilizzato nella scienza per condurre test di controllo randomizzati o per esperimenti in cieco.
L'esempio in cui i nomi di 25 dipendenti su 250 sono scelti a caso è un esempio del metodo della lotteria sul lavoro. A ciascuno dei 250 dipendenti verrebbe assegnato un numero compreso tra 1 e 250, dopo di che 25 di quei numeri sarebbero stati scelti a caso.
Poiché gli individui che costituiscono il sottoinsieme del gruppo più ampio vengono scelti a caso, ogni individuo nel grande insieme di popolazione ha la stessa probabilità di essere selezionato. Questo crea, nella maggior parte dei casi, un sottoinsieme equilibrato che porta il maggior potenziale per rappresentare il gruppo più ampio nel suo insieme, libero da ogni pregiudizio.
Per popolazioni più numerose, un metodo di lotteria manuale può essere piuttosto oneroso. La selezione di un campione casuale da una vasta popolazione di solito richiede un processo generato dal computer, con cui viene utilizzata la stessa metodologia del metodo della lotteria, solo le assegnazioni dei numeri e le successive selezioni sono eseguite da computer, non umani.
Spazio all'errore
Con un semplice campione casuale, deve esserci spazio per l'errore rappresentato da una varianza più e meno (errore di campionamento). Per esempio, se in un liceo di 1, 000 studenti doveva essere condotto un sondaggio per determinare quanti studenti sono mancini, il campionamento casuale può determinare che otto dei 100 campionati sono mancini. La conclusione sarebbe che l'8% della popolazione studentesca del liceo è mancina, quando in realtà la media globale sarebbe più vicina al 10%.
Lo stesso vale indipendentemente dall'argomento. Un sondaggio sulla percentuale della popolazione studentesca che ha gli occhi verdi o è fisicamente inabile risulterà in una probabilità matematica basata su un semplice sondaggio casuale, ma sempre con una varianza più o meno. L'unico modo per avere un tasso di precisione del 100% sarebbe quello di rilevare tutti 1, 000 studenti che, mentre possibile, sarebbe poco pratico.
Campione casuale semplice e casuale stratificato
Campioni casuali semplici e campioni casuali stratificati sono entrambi strumenti di misurazione statistica. Un semplice campione casuale viene utilizzato per rappresentare l'intera popolazione di dati. Un campione casuale stratificato divide la popolazione in gruppi più piccoli, o strati, sulla base di caratteristiche condivise.
A differenza dei semplici campioni casuali, campioni casuali stratificati vengono utilizzati con popolazioni che possono essere facilmente suddivise in diversi sottogruppi o sottoinsiemi. Questi gruppi si basano su determinati criteri, quindi gli elementi di ciascuno vengono scelti a caso in proporzione alla dimensione del gruppo rispetto alla popolazione.
Questo metodo di campionamento significa che ci saranno selezioni da ciascun diverso gruppo, la cui dimensione si basa sulla sua proporzione rispetto all'intera popolazione. Ma i ricercatori devono garantire che gli strati non si sovrappongano. Ogni punto della popolazione deve appartenere solo a uno strato, quindi ogni punto si esclude a vicenda. Strati sovrapposti aumenterebbero la probabilità che alcuni dati siano inclusi, distorcendo così il campione.
Vantaggi e svantaggi dei campioni casuali semplici
Mentre semplici campioni casuali sono facili da usare, presentano svantaggi chiave che possono rendere inutili i dati.
Vantaggi
La facilità d'uso rappresenta il più grande vantaggio del semplice campionamento casuale. A differenza dei metodi di campionamento più complicati, come il campionamento casuale stratificato e il campionamento probabilistico, non c'è bisogno di dividere la popolazione in sottopopolazioni o fare altri passi prima di selezionare a caso i membri della popolazione.
Un semplice campione casuale è pensato per essere una rappresentazione imparziale di un gruppo. È considerato un modo equo per selezionare un campione da una popolazione più ampia poiché ogni membro della popolazione ha le stesse possibilità di essere selezionato.
Sebbene il semplice campionamento casuale sia inteso come un approccio imparziale al rilevamento, possono verificarsi errori di selezione del campione. Quando un campione della popolazione più ampia non è sufficientemente inclusivo, la rappresentazione dell'intera popolazione è distorta e richiede tecniche di campionamento aggiuntive.
Svantaggi
Un errore di campionamento può verificarsi con un semplice campione casuale se il campione non riflette accuratamente la popolazione che dovrebbe rappresentare. Per esempio, nel nostro campione casuale semplice di 25 dipendenti, sarebbe possibile prelevare 25 uomini anche se la popolazione fosse composta da 125 donne e 125 uomini.
Per questa ragione, il campionamento casuale semplice è più comunemente usato quando il ricercatore sa poco della popolazione. Se il ricercatore ne sapesse di più, sarebbe meglio usare una tecnica di campionamento diversa, come il campionamento casuale stratificato, che aiuta a tenere conto delle differenze all'interno della popolazione, come l'età, corsa, o di genere. Altri svantaggi includono il fatto che per il campionamento da grandi popolazioni, il processo può richiedere molto tempo e denaro rispetto ad altri metodi.
Perché un semplice campione casuale è semplice?
Non esiste un metodo più semplice per estrarre un campione di ricerca da una popolazione più ampia rispetto al semplice campionamento casuale. La selezione di un numero sufficiente di soggetti in modo completamente casuale dalla popolazione più ampia produce anche un campione che può essere rappresentativo del gruppo studiato.
Quali sono alcuni svantaggi di un semplice campione casuale?
Tra gli svantaggi di questa tecnica vi sono la difficoltà di accedere agli intervistati che possono essere tratti dalla popolazione più ampia, tempo maggiore, maggiori costi, e il fatto che il pregiudizio può ancora verificarsi in determinate circostanze.
Che cos'è un campione casuale stratificato?
Un campione casuale stratificato, a differenza di un semplice pareggio, prima divide la popolazione in gruppi più piccoli, o strati, sulla base di caratteristiche condivise. Perciò, una strategia di campionamento stratificato assicurerà che i membri di ciascun sottogruppo siano inclusi nell'analisi dei dati. Il campionamento stratificato viene utilizzato per evidenziare le differenze tra i gruppi di una popolazione, rispetto al semplice campionamento casuale, che tratta tutti i membri di una popolazione come uguali, con la stessa probabilità di essere campionati.
Come vengono utilizzati i campioni casuali?
L'utilizzo di un semplice campionamento casuale consente ai ricercatori di fare generalizzazioni su una popolazione specifica e tralasciare qualsiasi distorsione. Utilizzando tecniche statistiche, si possono fare inferenze e previsioni sulla popolazione senza dover rilevare o raccogliere dati da ogni individuo di quella popolazione.
-

Come la tecnologia blockchain e l'intelligenza artificiale possono catalizzare la ripresa economica nel 2021
Questo è stato un anno difficile per sopravvivere e prosperare economicamente. Con un drastico tasso di aumento della disoccupazione e le imprese ancora alle prese con minacce esistenziali, questi son
-

11 cose che ogni investitore del mercato azionario dovrebbe sapere
Quando ho iniziato a investire nel 2007, Ho comprato le mie prime azioni senza fare molte ricerche. Di fatto, Ho fatto più ricerche sullacquisto della mia prima TV a schermo piatto rispetto alle azion
-

Il 34% dei lavoratori ha commesso questo errore con i propri risparmi per la pensione
I costi della pensione salgono a causa dellaumento dei prezzi, preoccupazioni per linflazione Lamministrazione della sicurezza sociale sta considerando di aumentare i pagamenti pensionistici il pros
-
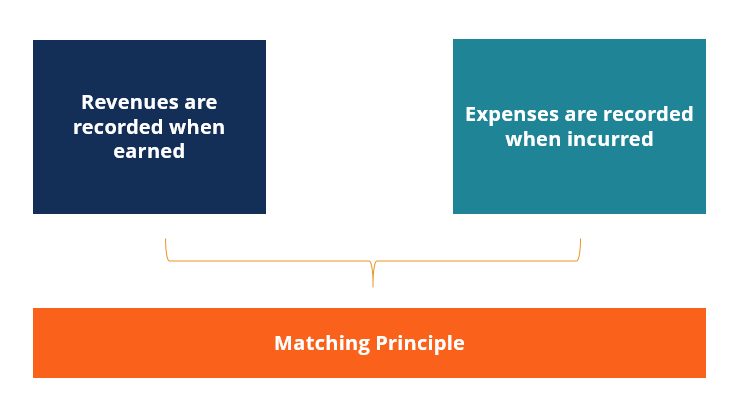
Adeguamento delle registrazioni:perché abbiamo bisogno di adeguare le registrazioni del diario?
Le registrazioni di rettifica sono necessarie alla fine di ogni periodo fiscale per allineare le entrate e le spese al periodo giusto, in accordo con il principio di corrispondenzaPrincipio di corrisp
finanza
-
 Il 50% degli anziani non mantiene i benefici della sicurezza sociale:ecco perché
Il 50% degli anziani non mantiene i benefici della sicurezza sociale:ecco perché La previdenza sociale rappresenta oggi unimportante fonte di reddito per milioni di anziani, con il destinatario medio che raccoglie circa $ 1, 500 al mese, o poco più di $ 18, 000 allanno. Il problem...
-
 Tecniche di monitoraggio e valutazione del progetto
Tecniche di monitoraggio e valutazione del progetto I grafici vengono utilizzati abitualmente nel monitoraggio e nella valutazione dei progetti per misurare i progressi. Il Project Management Institute definisce un progetto come uno sforzo temporaneo ...
-
 Come calcolare lo stipendio annuale dal salario orario
Come calcolare lo stipendio annuale dal salario orario Molti lavori sono retribuiti in base a una tariffa oraria anziché a uno stipendio annuale suddiviso in importi predeterminati per ciascun periodo di paga. Generalmente, questo non fa alcuna differenza...
-
 Come ho risparmiato $ 500 extra al mese durante la pandemia?
Come ho risparmiato $ 500 extra al mese durante la pandemia? Molti o tutti i prodotti qui provengono dai nostri partner che ci pagano una commissione. È così che guadagniamo. Ma la nostra integrità editoriale garantisce che le opinioni dei nostri esperti non si...